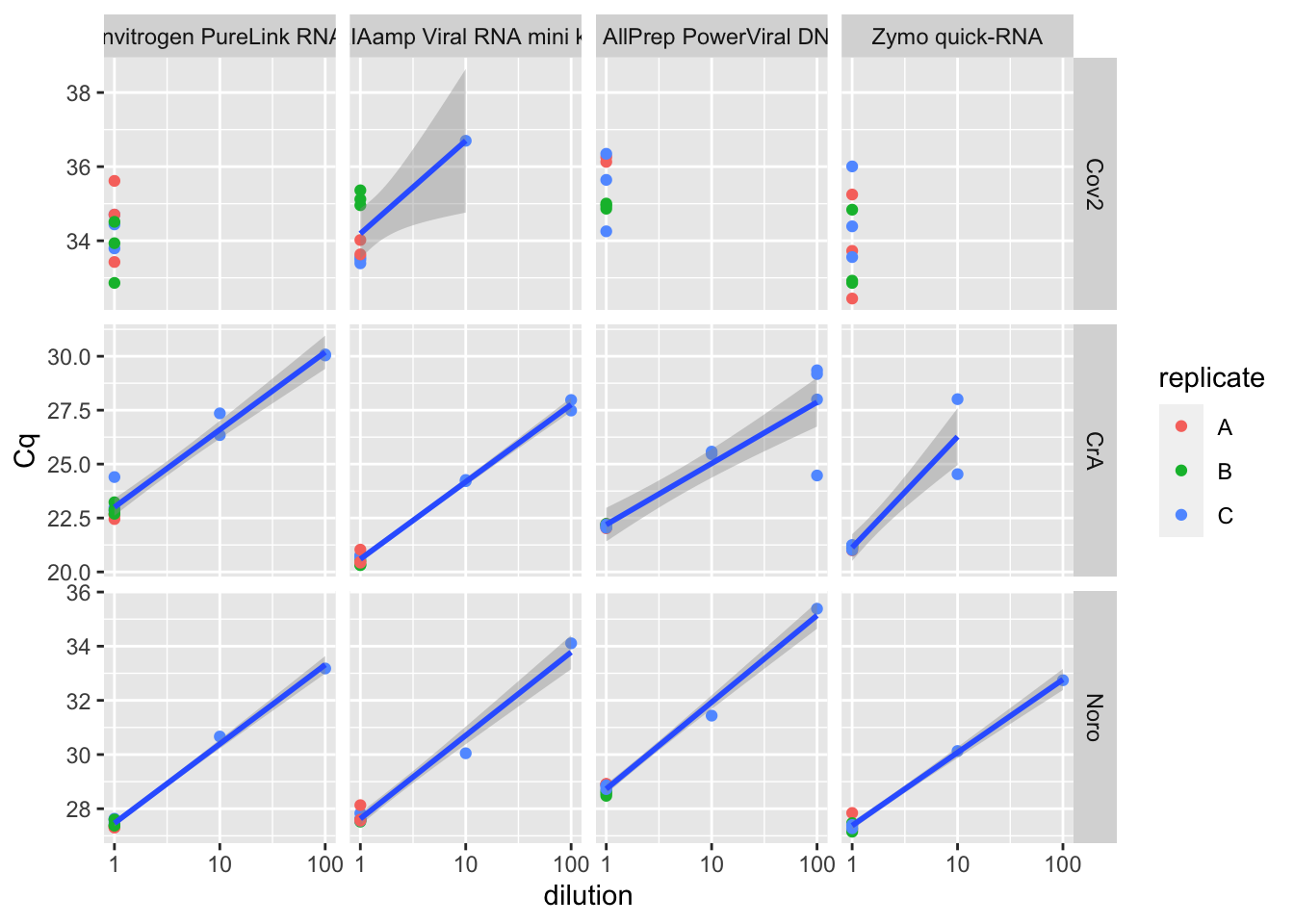
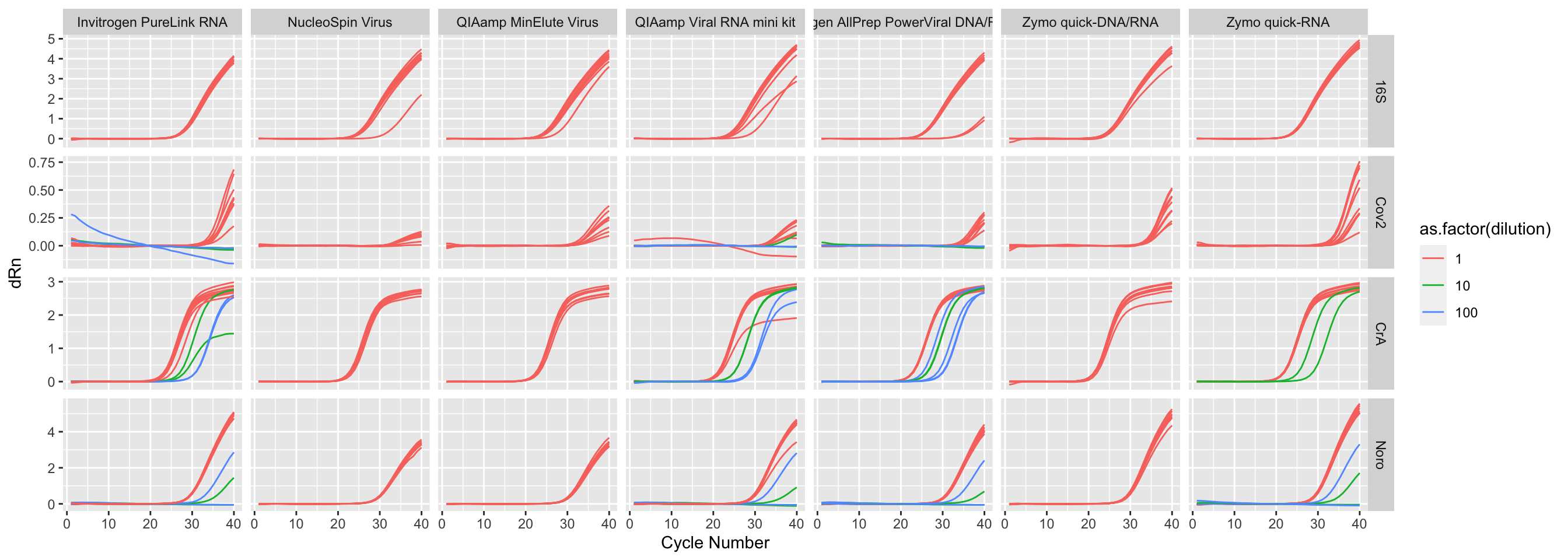
Rows: 369
Columns: 35
$ Well <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14,…
$ `Well Position` <chr> "A1", "A2", "A3", "A4", "A5", "A6", "A7", "A8"…
$ Omit <lgl> FALSE, FALSE, FALSE, FALSE, FALSE, FALSE, FALS…
$ Sample.x <chr> "1A", "1A", "1A", "3C", "3C", "3C", "6B", "6B"…
$ Target <chr> "Cov2", "Cov2", "Cov2", "Cov2", "Cov2", "Cov2"…
$ Task <chr> "UNKNOWN", "UNKNOWN", "UNKNOWN", "UNKNOWN", "U…
$ Reporter <chr> "FAM", "FAM", "FAM", "FAM", "FAM", "FAM", "FAM…
$ Quencher <chr> "NFQ-MGB", "NFQ-MGB", "NFQ-MGB", "NFQ-MGB", "N…
$ `Amp Status` <chr> "AMP", "AMP", "AMP", "AMP", "AMP", "AMP", "NO_…
$ `Amp Score` <dbl> 1.1701024, 1.0212594, 1.1604009, 1.1057531, 1.…
$ `Curve Quality` <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ `Result Quality Issues` <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ Cq <dbl> 32.44077, 35.24757, 33.72678, 34.44077, 34.704…
$ `Cq Confidence` <dbl> 0.9451320, 0.9773032, 0.9759027, 0.9634213, 0.…
$ `Cq Mean` <dbl> 33.80504, 33.80504, 33.80504, 34.31332, 34.313…
$ `Cq SD` <dbl> 1.4050310, 1.4050310, 1.4050310, 0.4683633, 0.…
$ `Auto Threshold` <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE…
$ Threshold <dbl> 0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04, 0.04…
$ `Auto Baseline` <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE…
$ `Baseline Start` <dbl> 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3, 3…
$ `Baseline End` <dbl> 29, 32, 30, 31, 31, 31, 31, 31, 31, 21, 21, 21…
$ Sample.y <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…
$ Sample <chr> "1A", "1A", "1A", "3C", "3C", "3C", "6B", "6B"…
$ Sample_ID <chr> "1A", "1A", "1A", "3C", "3C", "3C", "6B", "6B"…
$ dilution <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ replicate <chr> "A", "A", "A", "C", "C", "C", "B", "B", "B", N…
$ quantity <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, 1000, 1000…
$ Extraction_kit <chr> "Zymo quick-RNA", "Zymo quick-RNA", "Zymo quic…
$ Short_kit <chr> "1_ZR", "1_ZR", "1_ZR", "3_IPL", "3_IPL", "3_I…
$ `Kit Batch` <dbl> 1, 1, 1, 1, 1, 1, 3, 3, 3, NA, NA, NA, 1, 1, 1…
$ Elution_volume <dbl> 30, 30, 30, 100, 100, 100, 80, 80, 80, NA, NA,…
$ Elution_format <chr> "15*2", "15*2", "15*2", "50*2", "50*2", "50*2"…
$ Brand <chr> "Zymo", "Zymo", "Zymo", "Invitrogen", "Invitro…
$ NA_Target <chr> "RNA", "RNA", "RNA", "RNA", "RNA", "RNA", "RNA…
$ FP_sampleID <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA…